
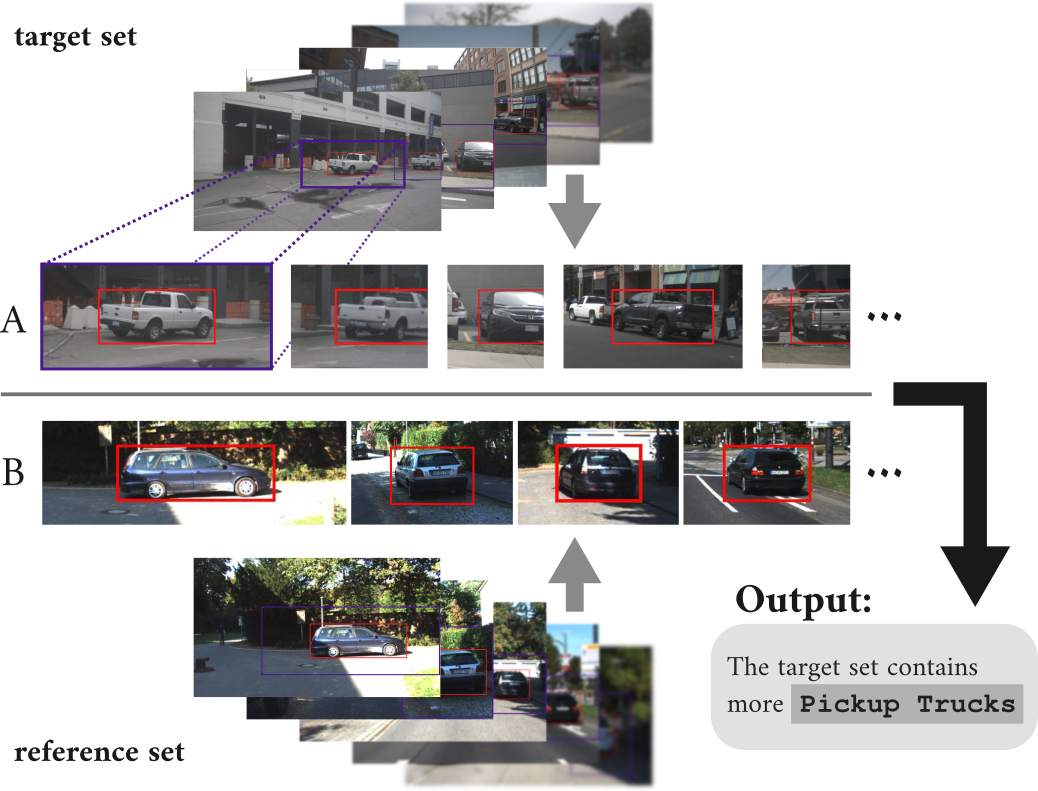
Modern autonomous driving systems rely on large and continuously growing datasets. While collecting and processing such data has become increasingly efficient, understanding its composition remains a major challenge. In particular, identifying subtle differences, biases, or gaps in data is essential for ensuring robustness and safety, yet difficult to achieve with existing tools.
This research investigates methods for automatically analyzing and comparing subsets of visual data from autonomous driving. The central idea is to describe differences between data subsets in natural language, providing an intuitive and scalable way to gain insight into dataset characteristics. Instead of relying solely on predefined labels or metadata, the approach leverages modern vision-language models to extract meaningful, human-readable descriptions directly from image data.